1 Basic statistical results
1.1 Cumulative and probability density funtions (c.d.f. and p.d.f.)
Definition 1.1 (Cumulative distribution function (c.d.f.)) The random variable (r.v.) \(X\) admits the cumulative distribution function \(F\) if, for all \(a\): \[ F(a)=\mathbb{P}(X \le a). \]
Definition 1.2 (Probability distribution function (p.d.f.)) A continuous random variable \(X\) admits the probability density function \(f\) if, for all \(a\) and \(b\) such that \(a<b\): \[ \mathbb{P}(a < X \le b) = \int_{a}^{b}f(x)dx, \] where \(f(x) \ge 0\) for all \(x\).
In particular, we have: \[\begin{equation} f(x) = \lim_{\varepsilon \rightarrow 0} \frac{\mathbb{P}(x < X \le x + \varepsilon)}{\varepsilon} = \lim_{\varepsilon \rightarrow 0} \frac{F(x + \varepsilon)-F(x)}{\varepsilon}.\tag{1.1} \end{equation}\] and \[ F(a) = \int_{-\infty}^{a}f(x)dx. \] This web interface illustrates the link between p.d.f. and c.d.f. Nonparametric estimates of p.d.f. are obtained by kernel-based methods (see this extra material).
Definition 1.3 (Joint cumulative distribution function (c.d.f.)) The random variables \(X\) and \(Y\) admit the joint cumulative distribution function \(F_{XY}\) if, for all \(a\) and \(b\): \[ F_{XY}(a,b)=\mathbb{P}(X \le a,Y \le b). \]
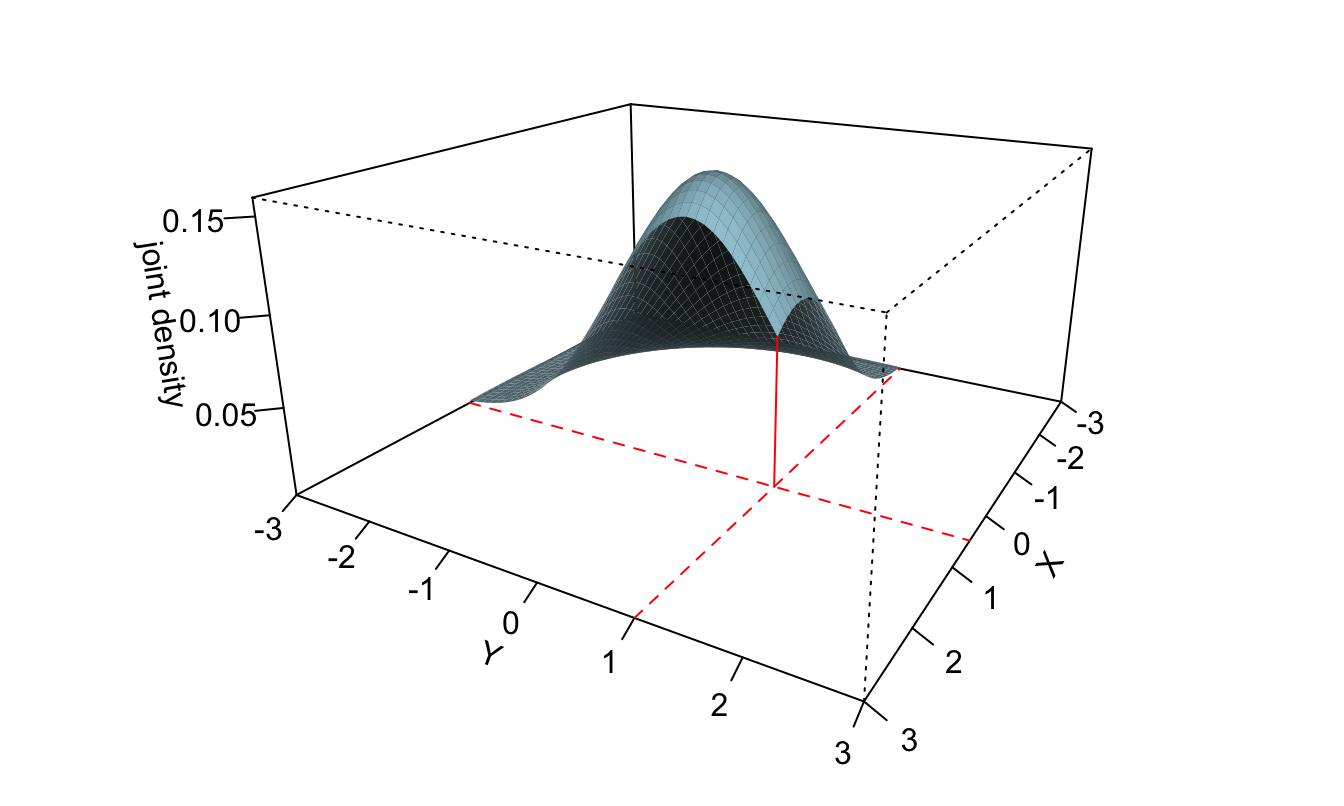
Figure 1.1: The volume between the horizontal plane (\(z=0\)) and the surface is equal to \(F_{XY}(0.5,1)=\mathbb{P}(X<0.5,Y<1)\).
Definition 1.4 (Joint probability density function (p.d.f.)) The continuous random variables \(X\) and \(Y\) admit the joint p.d.f. \(f_{XY}\), where \(f_{XY}(x,y) \ge 0\) for all \(x\) and \(y\), if: \[ \mathbb{P}(a < X \le b,c < Y \le d) = \int_{a}^{b}\int_{c}^{d}f_{XY}(x,y)dx dy, \quad \forall a \le b,\;c \le d. \]
In particular, we have: \[\begin{eqnarray*} &&f_{XY}(x,y)\\ &=& \lim_{\varepsilon \rightarrow 0} \frac{\mathbb{P}(x < X \le x + \varepsilon,y < Y \le y + \varepsilon)}{\varepsilon^2} \\ &=& \lim_{\varepsilon \rightarrow 0} \frac{F_{XY}(x + \varepsilon,y + \varepsilon)-F_{XY}(x,y + \varepsilon)-F_{XY}(x + \varepsilon,y)+F_{XY}(x,y)}{\varepsilon^2}. \end{eqnarray*}\]
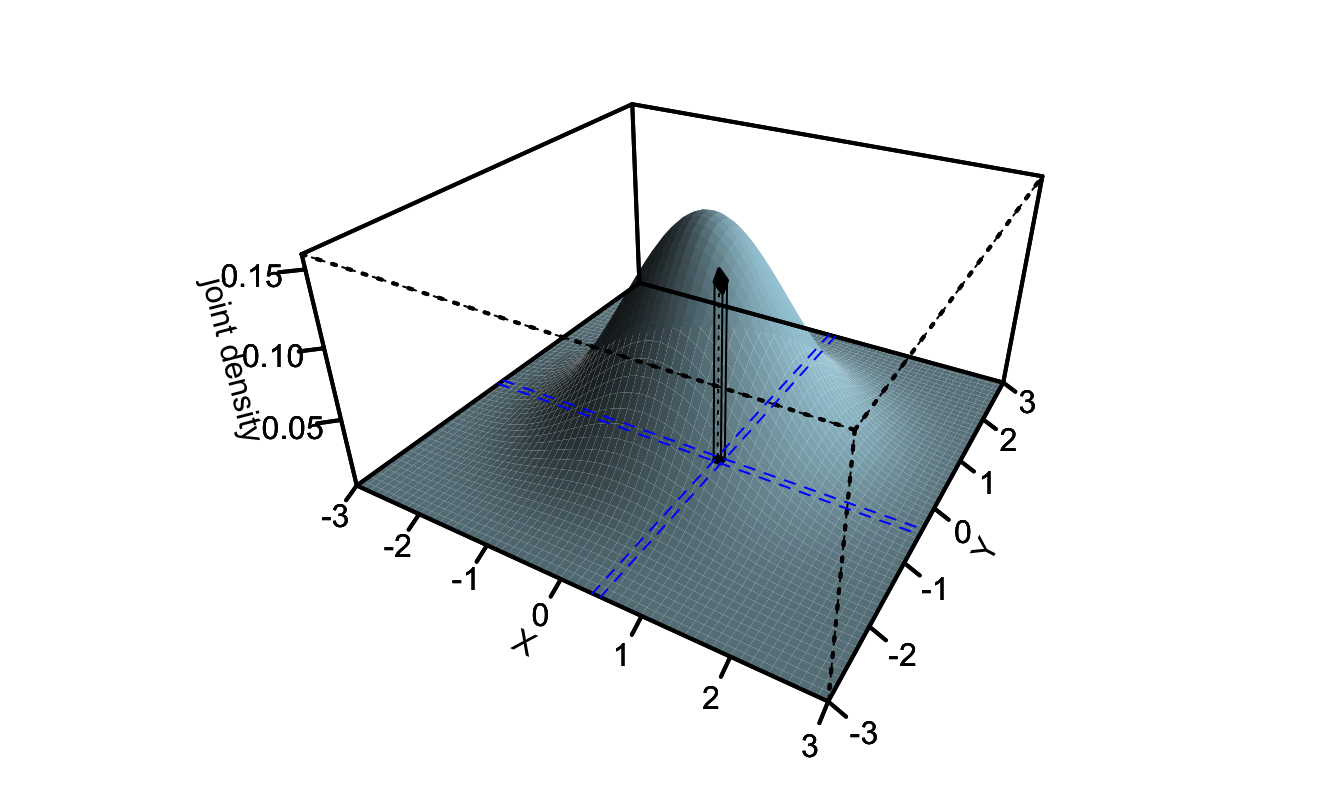
Figure 1.2: Assume that the basis of the black column is defined by those points whose \(x\)-coordinates are between \(x\) and \(x+\varepsilon\) and \(y\)-coordinates are between \(y\) and \(y+\varepsilon\). Then the volume of the black column is equal to \(\mathbb{P}(x < X \le x+\varepsilon,y < Y \le y+\varepsilon)\), which is approximately equal to \(f_{XY}(x,y)\varepsilon^2\) if \(\varepsilon\) is small.
Figure 1.3 illustrates why we have \[\begin{eqnarray*} &&\mathbb{P}(x < X \le x + \varepsilon,y < Y \le y + \varepsilon)\\ &=& F_{XY}(x + \varepsilon,y + \varepsilon)-F_{XY}(x,y + \varepsilon)-F_{XY}(x + \varepsilon,y)+F_{XY}(x,y). \end{eqnarray*}\] Let us denote by \(P_\Omega\) the probability that the point of coordinate \((X,Y)\) is included in the \(\Omega\) area. We have: \[ P_{B} = P_{B+C+D+E} - P_{E+D} - P_{E+C} + P_E, \] which implies that \[\begin{eqnarray*} &&\mathbb{P}(x<X\le x+ \varepsilon,y<Y\le y+ \varepsilon) \\ &=& \mathbb{P}(X\le x+ \varepsilon,Y\le y+ \varepsilon) - \mathbb{P}(X\le x+ \varepsilon,Y\le y) - \mathbb{P}(X\le x,Y\le y+ \varepsilon)\\ &&+ \mathbb{P}(X\le x,Y\le y). \end{eqnarray*}\]
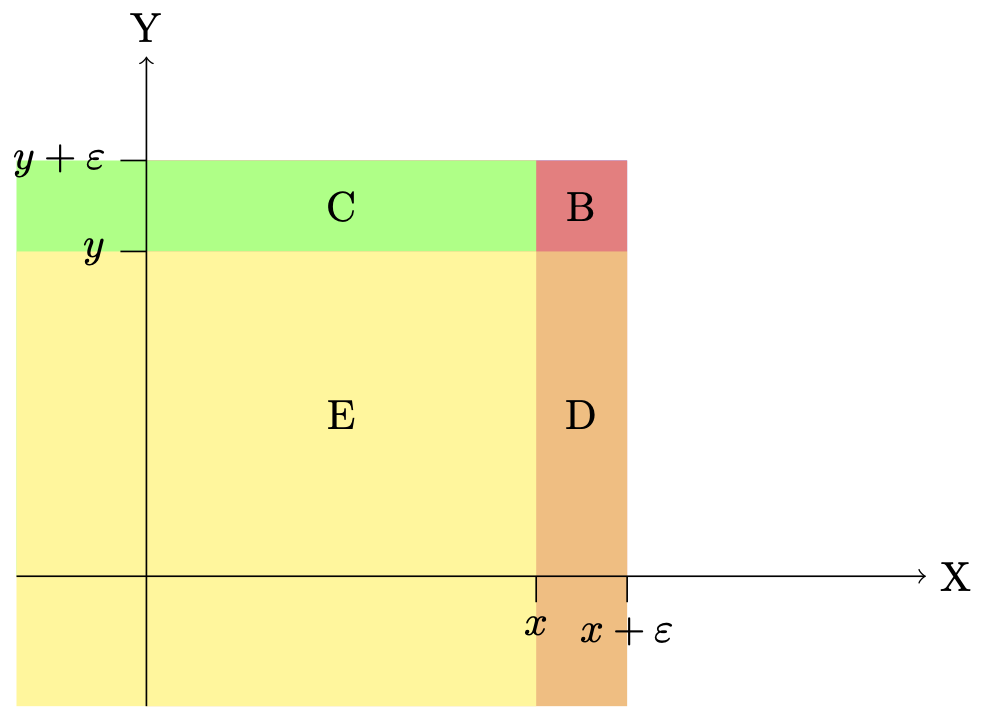
Figure 1.3: Area \(B+C+D+E\) encompasses the points with coordinates \((X,Y)\) such that \(X\le x+\varepsilon\) and \(Y \le y + \varepsilon\). Area \(D+E\) encompasses the points with coordinates \((X,Y)\) such that \(X\le x+\varepsilon\) and \(Y \le y\). Area \(C+E\) encompasses the points with coordinates \((X,Y)\) such that \(X\le x\) and \(Y \le y + \varepsilon\).
Definition 1.5 (Conditional probability distribution function) If \(X\) and \(Y\) are continuous r.v., then the distribution of \(X\) conditional on \(Y=y\), which we denote by \(f_{X|Y}(x,y)\), satisfies: \[ f_{X|Y}(x,y)=\lim_{\varepsilon \rightarrow 0} \frac{\mathbb{P}(x < X \le x + \varepsilon|Y=y)}{\varepsilon}. \]
Proposition 1.1 (Conditional probability distribution function) We have \[ f_{X|Y}(x,y)=\frac{f_{XY}(x,y)}{f_Y(y)}. \]
Proof. We have: \[\begin{eqnarray*} f_{X|Y}(x,y)&=&\lim_{\varepsilon \rightarrow 0} \frac{\mathbb{P}(x < X \le x + \varepsilon|Y=y)}{\varepsilon}\\ &=&\lim_{\varepsilon \rightarrow 0} \frac{1}{\varepsilon}\mathbb{P}(x < X \le x + \varepsilon|y<Y\le y+\varepsilon)\\ &=&\lim_{\varepsilon \rightarrow 0} \frac{1}{\varepsilon}\frac{\mathbb{P}(x < X \le x + \varepsilon,y<Y\le y+\varepsilon)}{\mathbb{P}(y<Y\le y+\varepsilon)}\\ &=&\lim_{\varepsilon \rightarrow 0} \frac{1}{\varepsilon} \frac{\varepsilon^2f_{XY}(x,y)}{\varepsilon f_{Y}(y)}. \end{eqnarray*}\]
Definition 1.6 (Independent random variables) Consider two r.v., \(X\) and \(Y\), with respective c.d.f. \(F_X\) and \(F_Y\), and respective p.d.f. \(f_X\) and \(f_Y\).
These random variables are independent if and only if (iff) the joint c.d.f. of \(X\) and \(Y\) (see Def. 1.3) is given by: \[ F_{XY}(x,y) = F_{X}(x) \times F_{Y}(y), \] or, equivalently, iff the joint p.d.f. of \((X,Y)\) (see Def. 1.4) is given by: \[ f_{XY}(x,y) = f_{X}(x) \times f_{Y}(y). \]
We have the following:
- If \(X\) and \(Y\) are independent, \(f_{X|Y}(x,y)=f_{X}(x)\). This implies, in particular, that \(\mathbb{E}(g(X)|Y)=\mathbb{E}(g(X))\), where \(g\) is any function.
- If \(X\) and \(Y\) are independent, then \(\mathbb{E}(g(X)h(Y))=\mathbb{E}(g(X))\mathbb{E}(h(Y))\) and \(\mathbb{C}ov(g(X),h(Y))=0\), where \(g\) and \(h\) are any functions.
It is important to note that the absence of correlation between two variables is not a sufficient condition to have independence. Consider for instance the case where \(X=Y^2\), with \(Y \sim\mathcal{N}(0,1)\). In this case, we have \(\mathbb{C}ov(X,Y)=0\), but \(X\) and \(Y\) are not independent. Indeed, we have for instance \(\mathbb{E}(Y^2 \times X)=3\), which is not equal to \(\mathbb{E}(Y^2) \times \mathbb{E}(X)=1\). (If \(X\) and \(Y\) were independent, we should have \(\mathbb{E}(Y^2 \times X)=\mathbb{E}(Y^2) \times \mathbb{E}(X)\) according to point 2 above.)
1.2 Law of iterated expectations
Proposition 1.2 (Law of iterated expectations) If \(X\) and \(Y\) are two random variables and if \(\mathbb{E}(|X|)<\infty\), we have: \[ \boxed{\mathbb{E}(X) = \mathbb{E}(\mathbb{E}(X|Y)).} \]
Proof. (in the case where the p.d.f. of \((X,Y)\) exists) Let us denote by \(f_X\), \(f_Y\) and \(f_{XY}\) the probability distribution functions (p.d.f.) of \(X\), \(Y\) and \((X,Y)\), respectively. We have: \[ f_{X}(x) = \int f_{XY}(x,y) dy. \] Besides, we have (Bayes equality, Prop. 1.1): \[ f_{XY}(x,y) = f_{X|Y}(x,y)f_{Y}(y). \] Therefore: \[\begin{eqnarray*} \mathbb{E}(X) &=& \int x f_X(x)dx = \int x \underbrace{ \int f_{XY}(x,y) dy}_{=f_X(x)} dx =\int \int x f_{X|Y}(x,y)f_{Y}(y) dydx \\ & = & \int \underbrace{\left(\int x f_{X|Y}(x,y)dx\right)}_{\mathbb{E}[X|Y=y]}f_{Y}(y) dy = \mathbb{E} \left( \mathbb{E}[X|Y] \right). \end{eqnarray*}\]
Example 1.1 (Mixture of Gaussian distributions) By definition, \(X\) is drawn from a mixture of Gaussian distributions if: \[ X = \color{blue}{B \times Y_1} + \color{red}{(1-B) \times Y_2}, \] where \(B\), \(Y_1\) and \(Y_2\) are three independent variables drawn as follows: \[ B \sim \mbox{Bernoulli}(p),\quad Y_1 \sim \mathcal{N}(\mu_1,\sigma_1^2), \quad \mbox{and}\quad Y_2 \sim \mathcal{N}(\mu_2,\sigma_2^2). \]
Figure 1.4 displays the pdfs associated with three different mixtures of Gaussian distributions. (This web-interface allows to produce the pdf associated for any other parameterization.)
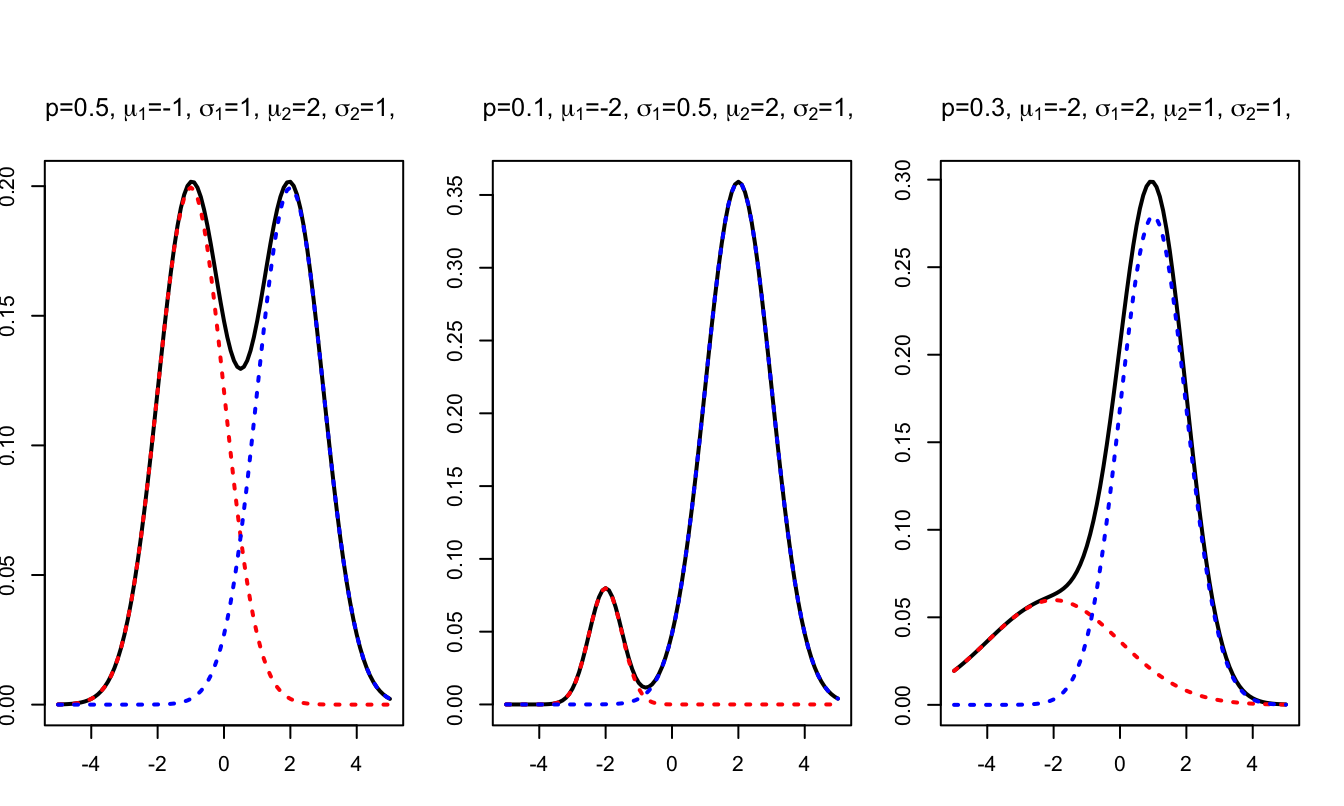
Figure 1.4: Example of pdfs of mixtures of Gaussian distribututions.
The law of iterated expectations gives: \[ \mathbb{E}(X) = \mathbb{E}(\mathbb{E}(X|B)) = \mathbb{E}(B\mu_1+(1-B)\mu_2)=p\mu_1 + (1-p)\mu_2. \]
Example 1.2 (Buffon (1733)'s needles) Suppose we have a floor made of parallel strips of wood, each the same width [\(w=1\)]. We drop a needle, of length \(1/2\), onto the floor. What is the probability that the needle crosses the grooves of the floor?
Let’s define the random variable \(X\) by \[ X = \left\{ \begin{array}{cl} 1 & \mbox{if the needle crosses a line}\\ 0 & \mbox{otherwise.} \end{array} \right. \] Conditionally on \(\theta\), it can be seen that we have \(\mathbb{E}(X|\theta)=\cos(\theta)/2\) (see Figure 1.5).
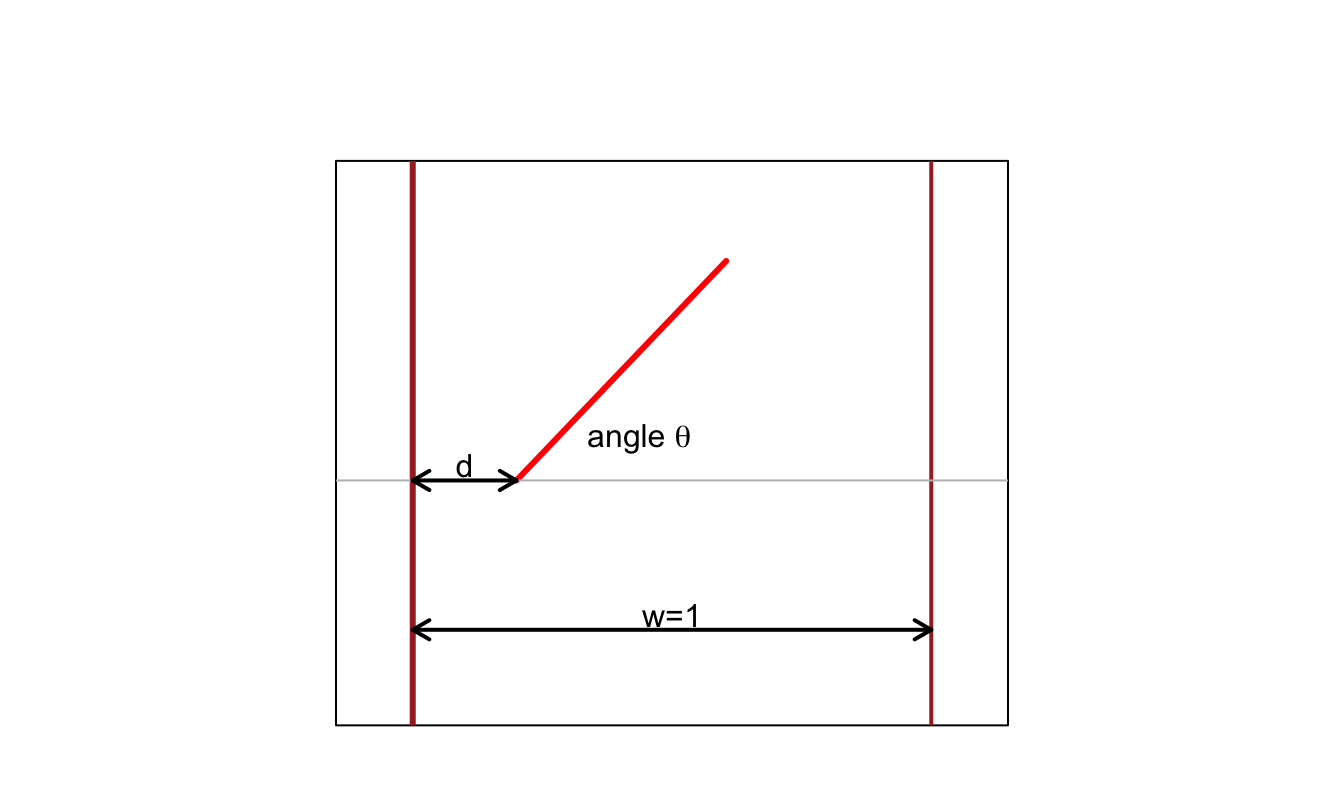
Figure 1.5: Schematic representation of the problem.
It is reasonable to assume that \(\theta\) is uniformly distributed on \([-\pi/2,\pi/2]\), therefore: \[ \mathbb{E}(X)=\mathbb{E}(\mathbb{E}(X|\theta))=\mathbb{E}(\cos(\theta)/2)=\int_{-\pi/2}^{\pi/2}\frac{1}{2}\cos(\theta)\left(\frac{d\theta}{\pi}\right)=\frac{1}{\pi}. \]
[This web-interface allows to simulate the present experiment (select Worksheet “Buffon’s needles”).]
1.3 Law of total variance
Proposition 1.3 (Law of total variance) If \(X\) and \(Y\) are two random variables and if the variance of \(X\) is finite, we have: \[ \boxed{\mathbb{V}ar(X) = \mathbb{E}(\mathbb{V}ar(X|Y)) + \mathbb{V}ar(\mathbb{E}(X|Y)).} \]
Proof. We have: \[\begin{eqnarray*} \mathbb{V}ar(X) &=& \mathbb{E}(X^2) - \mathbb{E}(X)^2\\ &=& \mathbb{E}(\mathbb{E}(X^2|Y)) - \mathbb{E}(X)^2\\ &=& \mathbb{E}(\mathbb{E}(X^2|Y) \color{blue}{- \mathbb{E}(X|Y)^2}) + \color{blue}{\mathbb{E}(\mathbb{E}(X|Y)^2)} - \color{red}{\mathbb{E}(X)^2}\\ &=& \mathbb{E}(\underbrace{\mathbb{E}(X^2|Y) - \mathbb{E}(X|Y)^2}_{\mathbb{V}ar(X|Y)}) + \underbrace{\mathbb{E}(\mathbb{E}(X|Y)^2) - \color{red}{\mathbb{E}(\mathbb{E}(X|Y))^2}}_{\mathbb{V}ar(\mathbb{E}(X|Y))}. \end{eqnarray*}\]
Example 1.3 (Mixture of Gaussian distributions (cont'd)) Consider the case of a mixture of Gaussian distributions (Example 1.1). We have: \[\begin{eqnarray*} \mathbb{V}ar(X) &=& \color{blue}{\mathbb{E}(\mathbb{V}ar(X|B))} + \color{red}{\mathbb{V}ar(\mathbb{E}(X|B))}\\ &=& \color{blue}{p\sigma_1^2+(1-p)\sigma_2^2} + \color{red}{p(1-p)(\mu_1 - \mu_2)^2}. \end{eqnarray*}\]
1.4 About consistent estimators
The objective of econometrics is to estimate parameters out of data observations (samples). Examples of parameters of interest include, among many others: causal effect of a variable on another, elasticities, parameters defining some distribution of interest, preference parameters (risk aversion)…
Except in degenerate cases, the estimates are different from the “true” (or population) value. A good estimator is expected to converge to the true value when the sample size increases. That is, we are interested in the consistency of the estimator.
Denote by \(\hat\theta_n\) the estimate of \(\theta\) based on a sample of length \(n\). We say that \(\hat\theta\) is a consistent estimator of \(\theta\) if, for any \(\varepsilon>0\) (even if very small), the probability that \(\hat\theta_n\) is in \([\theta - \varepsilon,\theta + \varepsilon]\) goes to 1 when \(n\) goes to \(\infty\). Formally: \[ \lim_{n \rightarrow + \infty} \mathbb{P}\left(\hat\theta_n \in [\theta - \varepsilon,\theta + \varepsilon]\right) = 1. \]
That is, \(\hat\theta\) is a consistent estimator if \(\hat\theta_n\) converges in probability (Def. 9.14) to \(\theta\). Note that there exist different types of stochastic convergence.1
Example 1.4 (Example of non-convergent estimator) Assume that \(X_i \sim i.i.d. \mbox{Cauchy}\) with a location parameter of 1 and a scale parameter of 1 (Def. 9.12). The sample mean \(\bar{X}_n = \frac{1}{n}\sum_{i=1}^{n} X_i\) does not converge in probability. This is because a Cauchy distribution has no mean; hence the law of large numbers (Theorem 2.1) does not apply.
N <- 5000
X <- rcauchy(N)
X.bar <- cumsum(X)/(1:N)
par(plt=c(.1,.95,.3,.85),mfrow=c(1,2))
plot(X,type="l",xlab="sample size (n)",
ylab="",main=expression(X[n]),lwd=2)
plot(X.bar,type="l",xlab="sample size (n)",
ylab="",main=expression(bar(X)[n]),lwd=2)
abline(h=0,lty=2,col="grey")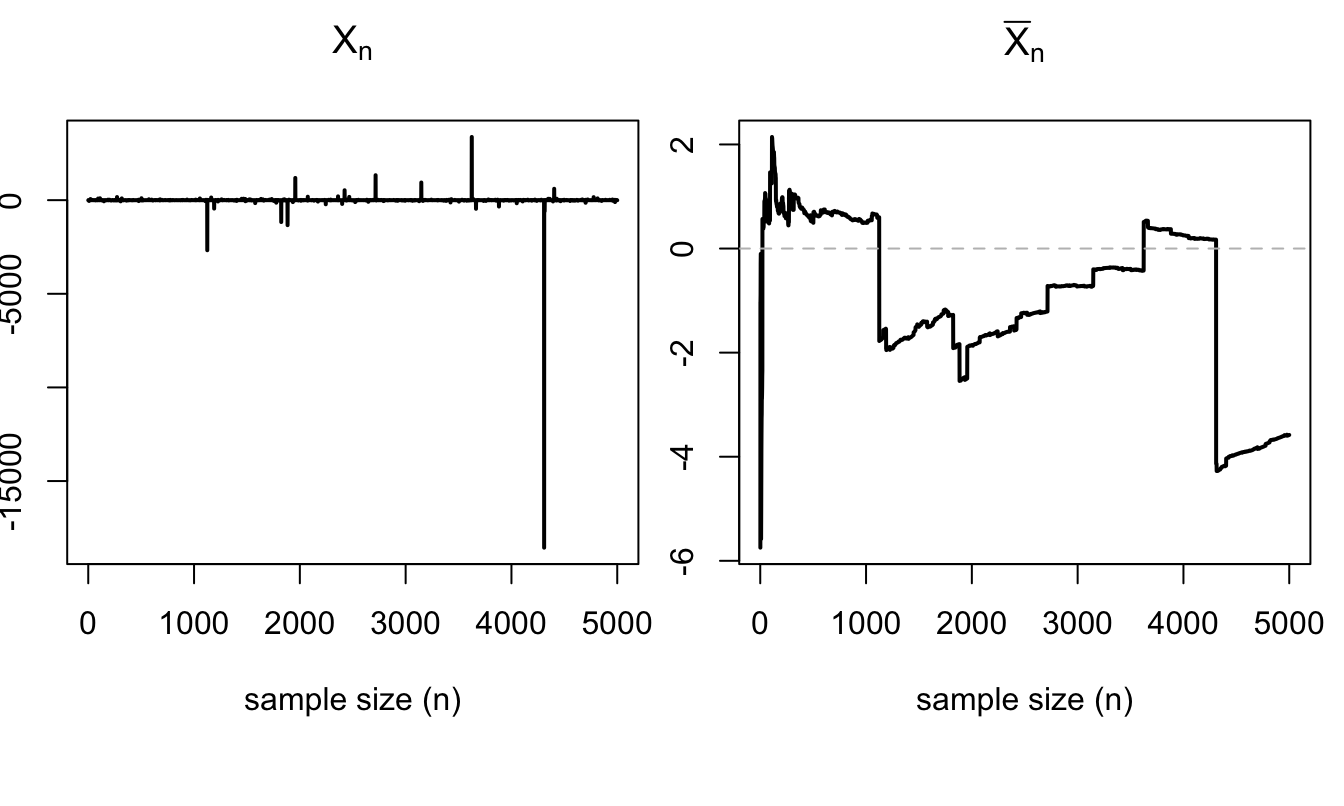
Figure 1.6: Simulation of \(\bar{X}_n\) when \(X_i \sim i.i.d. \mbox{Cauchy}\).